爛題,時間複雜度跟預想不符==
據說可以O(n^3),但O(n^3lgn)就可以在時限內過了
害我想很久,爛題><
http://codepad.org/2NTZ93Va
2012年7月30日 星期一
2012年7月29日 星期日
AC自動機(為什麼講義裡沒有="=)
Aho Corasick Automaton
(還是覺得很煩,為什麼講義裡沒有,害我一直以為不用用這個==)-> tioj 1723
其實他的想法跟KMP是一樣的,徹底了解KMP的人,對AC自動機一定可以很快的有體會。
搞不好,在想這題的時候,就會自然而然的想到這個作法,只是因為一些地方會覺得這個作法不可行,但其實稍做優化,就可以在時限內解決。
=================即將進入正文=================
他聽起來很厲害,一年前聽到的時候,覺得他是某種很高尚的東西,但他其實不過就是一個用來做多字串匹配的演算法。(而且他真的很像KMP)
還記得KMP嘛?概念就是做到某個前綴時發現不行,那就找他的某個後綴去試(failure function)AC自動機也是類似的概念。
AC自動機:
1. 先對多字串建出一棵Trie(我這個人不喜歡pointer,所以我都用array實作,開一個[N][26]的陣列。但因為N很大,算一下其實會發現他會MLE,我試了好久,發現只要把它改成一維的,他好像就會把沒有存取過的點視為未使用,但開二維的他卻會因為你把[1][2]存了,而認為你使用了所有[1][0]~[1][25]的所有空間而認定你MLE了,這只是個偷吃布的怪作法,但tioj可以騙到,搞不好連自己的電腦都可以這樣騙?!)
2. 用類似的方法建出failure function(因為你要做的是先求深度淺的再慢慢往較深的地方走,就跟KMP一樣,所以通常會使用BFS)
3. 要多記錄output function(他其實跟failure function很像,但是因為這裡面會有很多個匹配字串,所以當你發現某一個匹配字串被匹配時,你要把它所有也是某個匹配字串的后綴都印出來,或做一些操作,製作方式可以直接拿failure function過來,只要確定他是某個匹配字串即可)
4. 開始匹配!(基本上跟KMP一樣,除了最後找到的時候,要遞迴一下output function)
時間複雜度:
1. O(n)(阿就Trie阿)
2. O(n)(理由與KMP相同)
3. O(n)(理由與2. 相同)
4. O(n)+O(m)+O(K)(這裡比較特別,前兩個跟KMP也是一樣的,O(K)卻是新的東西,他代表著所有的匹配字串總共在文章中幾次,這就是我說的會讓你以為不行的地方,但其實可以用各種方法把這問題去除掉,我是用sort的,但可以不要把所有的output function都做一遍,可以先改那個節點,最後再DP跑過去)
code: http://codepad.org/nh65NWcc
(還是覺得很煩,為什麼講義裡沒有,害我一直以為不用用這個==)-> tioj 1723
其實他的想法跟KMP是一樣的,徹底了解KMP的人,對AC自動機一定可以很快的有體會。
搞不好,在想這題的時候,就會自然而然的想到這個作法,只是因為一些地方會覺得這個作法不可行,但其實稍做優化,就可以在時限內解決。
=================即將進入正文=================
他聽起來很厲害,一年前聽到的時候,覺得他是某種很高尚的東西,但他其實不過就是一個用來做多字串匹配的演算法。(而且他真的很像KMP)
還記得KMP嘛?概念就是做到某個前綴時發現不行,那就找他的某個後綴去試(failure function)AC自動機也是類似的概念。
AC自動機:
1. 先對多字串建出一棵Trie(我這個人不喜歡pointer,所以我都用array實作,開一個[N][26]的陣列。但因為N很大,算一下其實會發現他會MLE,我試了好久,發現只要把它改成一維的,他好像就會把沒有存取過的點視為未使用,但開二維的他卻會因為你把[1][2]存了,而認為你使用了所有[1][0]~[1][25]的所有空間而認定你MLE了,這只是個偷吃布的怪作法,但tioj可以騙到,搞不好連自己的電腦都可以這樣騙?!)
2. 用類似的方法建出failure function(因為你要做的是先求深度淺的再慢慢往較深的地方走,就跟KMP一樣,所以通常會使用BFS)
3. 要多記錄output function(他其實跟failure function很像,但是因為這裡面會有很多個匹配字串,所以當你發現某一個匹配字串被匹配時,你要把它所有也是某個匹配字串的后綴都印出來,或做一些操作,製作方式可以直接拿failure function過來,只要確定他是某個匹配字串即可)
4. 開始匹配!(基本上跟KMP一樣,除了最後找到的時候,要遞迴一下output function)
時間複雜度:
1. O(n)(阿就Trie阿)
2. O(n)(理由與KMP相同)
3. O(n)(理由與2. 相同)
4. O(n)+O(m)+O(K)(這裡比較特別,前兩個跟KMP也是一樣的,O(K)卻是新的東西,他代表著所有的匹配字串總共在文章中幾次,這就是我說的會讓你以為不行的地方,但其實可以用各種方法把這問題去除掉,我是用sort的,但可以不要把所有的output function都做一遍,可以先改那個節點,最後再DP跑過去)
code: http://codepad.org/nh65NWcc
2012年7月27日 星期五
2012年7月22日 星期日
tioj 1735 k-口吃子字串
這題很好心的已經給你長度了-> k
所以其實一個東西只會對到唯一的另一個
也就是a[i]只需要判斷是否跟a[i-k]相同
然後這題就會轉成你去看這個01序列
有幾個開頭,使得接下來連續 k 個都是1即可
code: http://codepad.org/wB0Ma9Nj
所以其實一個東西只會對到唯一的另一個
也就是a[i]只需要判斷是否跟a[i-k]相同
然後這題就會轉成你去看這個01序列
有幾個開頭,使得接下來連續 k 個都是1即可
code: http://codepad.org/wB0Ma9Nj
tioj 1321 好多回文 ndromePali
怎麼覺得字串題用Z function都可以輕鬆解決?
只是奇偶的差別有點複雜就是了,但基本上並不難
code: http://codepad.org/tQ6o7ACP
只是奇偶的差別有點複雜就是了,但基本上並不難
code: http://codepad.org/tQ6o7ACP
umm~傅立葉轉換+小小Latex
這是為了專題所需,是很偏的東西
我覺得資訊的部分,還蠻簡單的,但在物理的部份就比較困難
但他實在是從物理開始的,所以從物理講起還是比較合理。
喔對了,在看下去前,希望先對複數平面,和些許微積分有初步體會
而你會在維基看到什麼『DFT』,『FFT』,『Fourier Series』,概念差不多,只是用處不同
================================
首先!你要知道一個很重要的等號(原因的話,基本上是因為他們在微分的性質上是相同的且在相乘時也有相同性質,亦可以說他們其實是一體兩面的)

再來!你要對『正交』,也就是運用在非幾何地方的垂直,有一些了解:(我個人覺得這個東西很像向量的內積<只有兩個相同時才會有值,若兩個向量垂直則會得到零>所以故意用了dot,但應該是都可以的)

至於為什麼的話其實很簡單,看一下前面說的,轉換成圖形,一目了然
傅立葉級數(Fourier Series):
你也可以叫他傅立葉展開,比較貼切他的本意。傅立葉在很久以前發現一個週期函數(舉個例就是9e^i2*(pi))可以拆成唯一的sin, cos線性組合,寫成式子如下。這個東西很明顯就是已經知道 f 函數的週期才下去拆的,而在下式,我們是假設 f 函數為以2pi為週期的函數。
其實從第一式可以看出她的週期是2pi的蹤跡,第一式因為他是sigma,也就是說k為整數(就是角速度),你便可從中體會到 f 函數是由一群週期為2pi的倍數的基波(sin或cos函數)所組成(你可能會有疑問,為什麼是2pi的倍數勒?看本篇最上面的等式你就會了解了)
至於第二式,則有點套套邏輯的感覺(但他並沒有),他在裡頭又套回了第一式(想像他是由多個不同頻率的波所組成),並且用了剛剛所謂的正交的方式,將bk取了出來~實在是非常有趣的一件事情。


傅立葉轉換(Fourier Transform):
最主要的用處,是將一個時間(t)對振幅(A)的圖(簡稱A-t圖)轉換成一個頻率(f)對振幅的圖(簡稱A-f圖)。說的更清楚一些,就是將一個看似週期函數的,做某種奇特的分解,將他變成無限多個基波的組合(有種泰勒的fu~)。(我們平常看的應該是第二式吧)
這個新的等式,看起來很不一樣,但其實改變的只有兩個地方:
1. 我剛剛有說在前一節用的是以2pi為週期,但這裡所要轉換的是不被認為是週期函數的函數(所以我才說很像泰勒,舉個例的話就像常態分布函數),因為你不知道他的週期,他有可能由很大週期的sinuoid所組成,所以必須要包含到所有的w(這裡用的就是平常物理上在用的角速度,他代表的也確實是角速度)
2. 就是第二式從-2pi~2pi變成-inf~inf,原因的話跟剛剛一樣,你想要包含這個某某函數的一切,但你不知道他的範圍,故必須要全部考慮進去才行。
剩下的,像是正交什麼的概念,皆由傅立葉級數一併帶過來。


離散傅立葉變換(Discrete Fourier Transform):


這部份的公式其實就像是直接從前面的FT所轉過來,所以就不多討論了。從這裡我們要從另一個方向來看這個問題,從資訊的角度來看。
假設你現在碰到的問題是這樣的:
給你兩個多項式A(x)和B(x),求C(x) = A(x)*B(x)。
最原始的方法就是將他們依照原本的公式,以O(n^2)的時間得到答案,但這實在是太慢了,我們不想要以這麼弱的時間求得,這裡我要給你們一個method使這個問題可以在O(nlgn)內求出來。
首先,我們要先對多項式有初步了解。
n 項多項式A(x)的表示法:
1. 係數式:就是平常寫的a0+a1*x+a2*x^2...an-1*x^n-1
(乘法所需時間:O(n^2))
2. 點值式:用n個(x,y)所表示,且y = A(x)且每個x皆相異
(乘法所需時間:O(n))
而你可以證明出一個有n個點的點值式寫成n項係數式(說的精準一點應該是一個最多n項,因為有可能高次項的係數為零),只會有一種寫法。
(Hint:其實你就是要解一個n元一次式,而由克拉馬公式可以知道,要有唯一解的充要條件便是delta不等於零,接著,你可以用數學歸納法證明出delta = product of( xk-xj ) for{ 0<=j<k<=n-1 },既然n個x皆不相同,則delta != 0,所以只有唯一解)
這時候,相信有認真看的人,腦中都會浮現一個想法,如果能很快的把係數式轉乘點值式,再以O(n)做乘法,最後再很快的轉回係數式,不就得到你想要的答案了嘛?苦苦思索,發現以平常的方法想要轉很快,還是得花上O(n^2)的時間,這不就跟原本一樣嘛?還要寫更長,所以在這裡我要給出一個演算法了!(是高斯發明的)
只要你選了好的x點,便可以在O(nlgn)的時間內,完成從係數式轉點值式的夢想。
在接下來的部分我們都把n當成是2^k,所以每次切半的n都會是偶數,至於在真實情況中,我們可以把n補乘2^k,最多變兩倍,並不會改變時間複雜度,就讓我們一起探究吧!
如果你有n項,那我們所選出的x值,便是使得 x^n = 1 的共n個解(我們分別叫他們w0~wn-1)而這裡用到的概念只有一個:
 (n項)
(n項)
 (n/2項)
(n/2項)
 (n/2項)
(n/2項)
這時,心機重的你可能已經發現了,如果我們定義了一個method叫做求A(w0~wn-1)(且w^n = 1),那你把他遞迴求A[0]和A[1],他在method中的 w' 剛好會是原本的 w^2 ,跟我們想要的一樣,所以我們便可以D&C的作法求出答案(細節的話,就自己想一下囉~)

其實多項式的乘法就是圓周卷積,而將其做傅立葉轉換後,就會變成直接乘法,是我們把傅立葉運用到資訊上所得到的結果,但你也可以把傅立葉轉換想成就是係數式轉點值式,全然看你想從哪個層面去認識他罷了。
對了,這裡面的數學式都是我用Latex打的,所以偷偷講一下他:
包住一群東西:打 {}
一群字:打 \mbox(...)
特殊字:打 \XXXX
上標:打 ^
下標:打 _
討論:打 \left\{ \begin{array}{rcl}...&...&...\\...&...&... \end{array} \right.
(rcl代表要幾塊東西,也可以打rc或rl...,而&就是分塊用的,而如果你要換行,則是打\\)
矩陣:打 \left( \begin{array}{rcl} ...&...&... \end{array} \right)
積分:打 \int_{-\infty}^{\infty}
(從負無限大積到無限大)
各種字元:CLICK HERE
我覺得資訊的部分,還蠻簡單的,但在物理的部份就比較困難
但他實在是從物理開始的,所以從物理講起還是比較合理。
喔對了,在看下去前,希望先對複數平面,和些許微積分有初步體會
而你會在維基看到什麼『DFT』,『FFT』,『Fourier Series』,概念差不多,只是用處不同
================================
首先!你要知道一個很重要的等號(原因的話,基本上是因為他們在微分的性質上是相同的且在相乘時也有相同性質,亦可以說他們其實是一體兩面的)

再來!你要對『正交』,也就是運用在非幾何地方的垂直,有一些了解:(我個人覺得這個東西很像向量的內積<只有兩個相同時才會有值,若兩個向量垂直則會得到零>所以故意用了dot,但應該是都可以的)
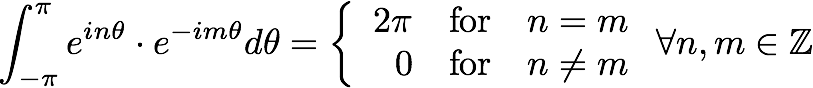
至於為什麼的話其實很簡單,看一下前面說的,轉換成圖形,一目了然
傅立葉級數(Fourier Series):
你也可以叫他傅立葉展開,比較貼切他的本意。傅立葉在很久以前發現一個週期函數(舉個例就是9e^i2*(pi))可以拆成唯一的sin, cos線性組合,寫成式子如下。這個東西很明顯就是已經知道 f 函數的週期才下去拆的,而在下式,我們是假設 f 函數為以2pi為週期的函數。
其實從第一式可以看出她的週期是2pi的蹤跡,第一式因為他是sigma,也就是說k為整數(就是角速度),你便可從中體會到 f 函數是由一群週期為2pi的倍數的基波(sin或cos函數)所組成(你可能會有疑問,為什麼是2pi的倍數勒?看本篇最上面的等式你就會了解了)
至於第二式,則有點套套邏輯的感覺(但他並沒有),他在裡頭又套回了第一式(想像他是由多個不同頻率的波所組成),並且用了剛剛所謂的正交的方式,將bk取了出來~實在是非常有趣的一件事情。


最主要的用處,是將一個時間(t)對振幅(A)的圖(簡稱A-t圖)轉換成一個頻率(f)對振幅的圖(簡稱A-f圖)。說的更清楚一些,就是將一個看似週期函數的,做某種奇特的分解,將他變成無限多個基波的組合(有種泰勒的fu~)。(我們平常看的應該是第二式吧)
這個新的等式,看起來很不一樣,但其實改變的只有兩個地方:
1. 我剛剛有說在前一節用的是以2pi為週期,但這裡所要轉換的是不被認為是週期函數的函數(所以我才說很像泰勒,舉個例的話就像常態分布函數),因為你不知道他的週期,他有可能由很大週期的sinuoid所組成,所以必須要包含到所有的w(這裡用的就是平常物理上在用的角速度,他代表的也確實是角速度)
2. 就是第二式從-2pi~2pi變成-inf~inf,原因的話跟剛剛一樣,你想要包含這個某某函數的一切,但你不知道他的範圍,故必須要全部考慮進去才行。
剩下的,像是正交什麼的概念,皆由傅立葉級數一併帶過來。


離散傅立葉變換(Discrete Fourier Transform):


假設你現在碰到的問題是這樣的:
給你兩個多項式A(x)和B(x),求C(x) = A(x)*B(x)。
最原始的方法就是將他們依照原本的公式,以O(n^2)的時間得到答案,但這實在是太慢了,我們不想要以這麼弱的時間求得,這裡我要給你們一個method使這個問題可以在O(nlgn)內求出來。
首先,我們要先對多項式有初步了解。
n 項多項式A(x)的表示法:
1. 係數式:就是平常寫的a0+a1*x+a2*x^2...an-1*x^n-1
(乘法所需時間:O(n^2))
2. 點值式:用n個(x,y)所表示,且y = A(x)且每個x皆相異
(乘法所需時間:O(n))
而你可以證明出一個有n個點的點值式寫成n項係數式(說的精準一點應該是一個最多n項,因為有可能高次項的係數為零),只會有一種寫法。
(Hint:其實你就是要解一個n元一次式,而由克拉馬公式可以知道,要有唯一解的充要條件便是delta不等於零,接著,你可以用數學歸納法證明出delta = product of( xk-xj ) for{ 0<=j<k<=n-1 },既然n個x皆不相同,則delta != 0,所以只有唯一解)
這時候,相信有認真看的人,腦中都會浮現一個想法,如果能很快的把係數式轉乘點值式,再以O(n)做乘法,最後再很快的轉回係數式,不就得到你想要的答案了嘛?苦苦思索,發現以平常的方法想要轉很快,還是得花上O(n^2)的時間,這不就跟原本一樣嘛?還要寫更長,所以在這裡我要給出一個演算法了!(是高斯發明的)
只要你選了好的x點,便可以在O(nlgn)的時間內,完成從係數式轉點值式的夢想。
在接下來的部分我們都把n當成是2^k,所以每次切半的n都會是偶數,至於在真實情況中,我們可以把n補乘2^k,最多變兩倍,並不會改變時間複雜度,就讓我們一起探究吧!
如果你有n項,那我們所選出的x值,便是使得 x^n = 1 的共n個解(我們分別叫他們w0~wn-1)而這裡用到的概念只有一個:
 (n項)
(n項) (n/2項)
(n/2項) (n/2項)
(n/2項)
相信平常愛寫程式的人,一看就知道這就是O(nlgn)了~所以我們的夢想實現了。不知道你們有沒有往上拉,我們剛剛所使用的公式,就是DFT的轉換公式呢!至於逆運算(也就是點值式轉係數式)則可以用原本正交的概念,湊出一個逆公式(其實不過就是把integrate轉乘summation),相信你湊出的逆公式就是DFT的逆轉換公式哩。(喔~對了,剛剛講的演算法就是所謂的快速傅立葉轉換,FFT,也是平常用在電路,訊號的一個快速演算法,同時也是使DFT在生活中廣受運用的一大原因)
其實多項式的乘法就是圓周卷積,而將其做傅立葉轉換後,就會變成直接乘法,是我們把傅立葉運用到資訊上所得到的結果,但你也可以把傅立葉轉換想成就是係數式轉點值式,全然看你想從哪個層面去認識他罷了。
對了,這裡面的數學式都是我用Latex打的,所以偷偷講一下他:
包住一群東西:打 {}
一群字:打 \mbox(...)
特殊字:打 \XXXX
上標:打 ^
下標:打 _
討論:打 \left\{ \begin{array}{rcl}...&...&...\\...&...&... \end{array} \right.
(rcl代表要幾塊東西,也可以打rc或rl...,而&就是分塊用的,而如果你要換行,則是打\\)
矩陣:打 \left( \begin{array}{rcl} ...&...&... \end{array} \right)
積分:打 \int_{-\infty}^{\infty}
(從負無限大積到無限大)
各種字元:CLICK HERE
2012年7月21日 星期六
tioj 1634 然後我哥就起笑了
搞笑提XD
測資是有多少阿==
跑這麼久...
我的想法有點像數學歸納法
如果在2^i之前可以做出 1 到 2^i-1的所有數字
那就可以把2^i的也全數放進去,就這樣。
code: http://codepad.org/GqzcIRk3
測資是有多少阿==
跑這麼久...
我的想法有點像數學歸納法
如果在2^i之前可以做出 1 到 2^i-1的所有數字
那就可以把2^i的也全數放進去,就這樣。
code: http://codepad.org/GqzcIRk3
2012年7月20日 星期五
tioj 1725 Massacre at Camp Happy
並不是什麼很難的字串提,他只是Z algorithm的基礎應用
但我卻WA了很多次,主要原因在於我一開始的Z_Maker根本是錯的
(放心,我前一篇的code是對的,喔對了!我四月po的似曾相識code是有問題的,所以我才會再po了STRINGS CODE這一篇)
因為我是看著演算法筆記學習的,但事實上他的講法是有問題的
1. 啟始點不可為 0,因為你的z[0]已經設定過了,這樣會產生不可預期的錯誤(以他預設的L, R都是零的情況,應該可以改成不會錯,但沒這必要阿)
2. 在判斷一個後綴是否可能再繼續下去,也要把連最後一個也一樣的情況都要判斷進去,因為如果下一個又一樣,那他的LCP是有可能加長的(聽不懂我講的且是照著演算法筆記學的人,寫完這提後就會有深刻了解)
code: http://codepad.org/guqpPxPc
但我卻WA了很多次,主要原因在於我一開始的Z_Maker根本是錯的
(放心,我前一篇的code是對的,喔對了!我四月po的似曾相識code是有問題的,所以我才會再po了STRINGS CODE這一篇)
因為我是看著演算法筆記學習的,但事實上他的講法是有問題的
1. 啟始點不可為 0,因為你的z[0]已經設定過了,這樣會產生不可預期的錯誤(以他預設的L, R都是零的情況,應該可以改成不會錯,但沒這必要阿)
2. 在判斷一個後綴是否可能再繼續下去,也要把連最後一個也一樣的情況都要判斷進去,因為如果下一個又一樣,那他的LCP是有可能加長的(聽不懂我講的且是照著演算法筆記學的人,寫完這提後就會有深刻了解)
code: http://codepad.org/guqpPxPc
Gusfield Algorithm
也就是俗稱的Z algorithm
概念也很簡單,就是記錄每個後綴與母字串的最長共同前綴
他的時間複雜度跟KMP是一樣的,都是O(n)
但我覺得他的概念比較簡單,實作方便
他的精隨在於:記錄比對到的最右界R,及比對到此右界的後綴起點L
並且可以分成三種情況討論:
1. 要比的後綴根本沒被比過 -> 就去比吧
2. 要比的後綴的前面部分已比過但長度未知 -> 繼續比吧
3. 要比的後綴的前面部分已比過且長度已知 -> 直接記錄吧
我的code: http://codepad.org/OPoY0Pu4
若要做字串匹配,直接把兩個字串黏在一起(要找的放在前面)
看哪些點的Z[]值 = 找尋字串的長度,便可知其出現的數量
有人會問這樣他的功能不是跟KMP一樣嘛?學他做什麼?
我覺得應該是為了增加另外一種想法吧!因為經過轉換後,就可以用在KMP所無法運用的地方了
所以在這邊稍稍分析一下兩者的差別:
KMP: 每個前綴與其後綴的次長共同前綴(最長的後綴)
Z_Vl: 每個後綴與母字串的最長共同前綴(單純的長度)
大致記得他們的差異,就可以在碰到題目時,適當的做運用。
概念也很簡單,就是記錄每個後綴與母字串的最長共同前綴
他的時間複雜度跟KMP是一樣的,都是O(n)
但我覺得他的概念比較簡單,實作方便
他的精隨在於:記錄比對到的最右界R,及比對到此右界的後綴起點L
並且可以分成三種情況討論:
1. 要比的後綴根本沒被比過 -> 就去比吧
2. 要比的後綴的前面部分已比過但長度未知 -> 繼續比吧
3. 要比的後綴的前面部分已比過且長度已知 -> 直接記錄吧
我的code: http://codepad.org/OPoY0Pu4
若要做字串匹配,直接把兩個字串黏在一起(要找的放在前面)
看哪些點的Z[]值 = 找尋字串的長度,便可知其出現的數量
有人會問這樣他的功能不是跟KMP一樣嘛?學他做什麼?
我覺得應該是為了增加另外一種想法吧!因為經過轉換後,就可以用在KMP所無法運用的地方了
所以在這邊稍稍分析一下兩者的差別:
KMP: 每個前綴與其後綴的次長共同前綴(最長的後綴)
Z_Vl: 每個後綴與母字串的最長共同前綴(單純的長度)
大致記得他們的差異,就可以在碰到題目時,適當的做運用。
2012年7月18日 星期三
Strings CODE
這裡是奉上我的code的小地方~
MP: 就是上一篇的內容
(code: http://codepad.org/JhbPTUVc)
KMP: MP加上一個優化:若 b[ i + 1] 跟 b[f[i] + 1] 相同時,比對b[ i+1]失敗,可跳過 b[ f[i]+1 ]
(code: http://codepad.org/SLlkwDJR)
SA, RA: 這部份跟之前在似曾相似裡的東西一模一樣,但code寫的不清不楚的,所以重寫一份
(code: http://codepad.org/QFHlMA4F)
LCP: 就是包括求h[]以得height[]最後再用ST做出O(nlgn)-O(1)的RMQ
(code: http://codepad.org/7hPyaKjm)
第一次寫完一題字串提:tioj 1306
(code: http://codepad.org/e8ke7V1f)
如果有人可以的話,寫完這提後,希望可以借看一下code,感謝> <
MP: 就是上一篇的內容
(code: http://codepad.org/JhbPTUVc)
KMP: MP加上一個優化:若 b[ i + 1] 跟 b[f[i] + 1] 相同時,比對b[ i+1]失敗,可跳過 b[ f[i]+1 ]
(code: http://codepad.org/SLlkwDJR)
SA, RA: 這部份跟之前在似曾相似裡的東西一模一樣,但code寫的不清不楚的,所以重寫一份
(code: http://codepad.org/QFHlMA4F)
LCP: 就是包括求h[]以得height[]最後再用ST做出O(nlgn)-O(1)的RMQ
(code: http://codepad.org/7hPyaKjm)
第一次寫完一題字串提:tioj 1306
(code: http://codepad.org/e8ke7V1f)
如果有人可以的話,寫完這提後,希望可以借看一下code,感謝> <
2012年7月16日 星期一
還記得SA數組嘛?
之前在似曾相識的那一提,有很認真的討論過關於SA數組的construction和他的概念等,並在最後面的地方,隱約提到了有關 h 數組的事情,也提到了幾個定理,但並沒有好好的講清楚,在這裡要將他們一一證明。
==============================要進入主題了~
Longest Common Prefix:(照字面上就是最長的共同前綴,而他確實是這樣的東西)
名詞解釋:
i =x j: 兩個後綴前x個字元相同
sa[i]: 第i名後綴是第幾個後綴
ra[i]: 第i個後綴是第幾名後綴
lcp( i, j ): 第i個後綴與第j個後綴的最長公共前綴
LCP( i, j ): 第i名後綴與第j名後綴的最長公共前綴(照字典序sort後)
h[i]: LCP( rank[i]-1, rank[i] )
-------------------------------------------------------------------------------------
一。 LCP Lemma: LCP( i, j ) = min( LCP( i, k ), LCP( k, j ) ); { i<=k<=j }
proof:
1. 設 x = min( LCP(i,k), LCP(k,j) ), 則i =x k 且 k =x j, 故LCP(i,j) >= x
2. 設LCP(i,j) > x, 則 i[x+1] = j[x+1].
因 i < k < j 且 i =x j =x k, 故 i[x+1]<=k[x+1]<=j[x+1].
因此i[x+1] = k[x+1] = j[x+1], 矛盾!!!!
3. 由1.和2.可知LCP(i,j) = x = min( LCP(i,k), LCP(k,j) ).
-------------------------------------------------------------------------------------
二。 LCP Theorem: LCP( i, j ) = min( LCP( k, k-1 ) ) { k = i+1~j }
proof:
1. j-i == 0 和 j-i == 1 皆成立
2. 若 j-i == m 成立,則LCP( i, j ) = min( LCP( k-1, k ) ) { k = i+1~j },
由LCP Lemma -> LCP( i-1, j ) = min( LCP(i-1, i ), LCP( i, j ) )
-> LCP( i-1, j ) = min( LCP( k-1, k ) ) { k = i~j } -> j-i == m+1成立
-------------------------------------------------------------------------------------
三。LCP Corollary: LCP( i, k ) <= LCP( j, k ) { i <= j <= k }
proof: LCP( i, k ) = min( LCP( i, j ), LCP( j, k ) ) <= LCP( j, k )
-------------------------------------------------------------------------------------
四。h[]數組的特性:h[i] >= h[i-1] - 1
proof:

==============================要進入主題了~
Longest Common Prefix:(照字面上就是最長的共同前綴,而他確實是這樣的東西)
名詞解釋:
i =x j: 兩個後綴前x個字元相同
sa[i]: 第i名後綴是第幾個後綴
ra[i]: 第i個後綴是第幾名後綴
lcp( i, j ): 第i個後綴與第j個後綴的最長公共前綴
LCP( i, j ): 第i名後綴與第j名後綴的最長公共前綴(照字典序sort後)
h[i]: LCP( rank[i]-1, rank[i] )
一。 LCP Lemma: LCP( i, j ) = min( LCP( i, k ), LCP( k, j ) ); { i<=k<=j }
proof:
1. 設 x = min( LCP(i,k), LCP(k,j) ), 則i =x k 且 k =x j, 故LCP(i,j) >= x
2. 設LCP(i,j) > x, 則 i[x+1] = j[x+1].
因 i < k < j 且 i =x j =x k, 故 i[x+1]<=k[x+1]<=j[x+1].
因此i[x+1] = k[x+1] = j[x+1], 矛盾!!!!
3. 由1.和2.可知LCP(i,j) = x = min( LCP(i,k), LCP(k,j) ).
-------------------------------------------------------------------------------------
二。 LCP Theorem: LCP( i, j ) = min( LCP( k, k-1 ) ) { k = i+1~j }
proof:
1. j-i == 0 和 j-i == 1 皆成立
2. 若 j-i == m 成立,則LCP( i, j ) = min( LCP( k-1, k ) ) { k = i+1~j },
由LCP Lemma -> LCP( i-1, j ) = min( LCP(i-1, i ), LCP( i, j ) )
-> LCP( i-1, j ) = min( LCP( k-1, k ) ) { k = i~j } -> j-i == m+1成立
-------------------------------------------------------------------------------------
三。LCP Corollary: LCP( i, k ) <= LCP( j, k ) { i <= j <= k }
proof: LCP( i, k ) = min( LCP( i, j ), LCP( j, k ) ) <= LCP( j, k )
-------------------------------------------------------------------------------------
四。h[]數組的特性:h[i] >= h[i-1] - 1
proof:
LCA和RMQ的詳細討論(?!)
又開始學新的東西,突然發現我了解的東西實在很少阿
今天要講的有LCA和RMQ(兩個關係匪淺的好玩有趣酷炫東西)
講完這個希望可以進入新的一個境界,並進入可怕的『字串』
=============================================入正文
LCA有兩種簡單的作法:
第一種:
我最常用的方法,就是用二分搜的方式。先以 O(nlgn) 做出parent[k][u],代表 u 往上2^k所到達的點,作法的精隨:parent[k+1][u] = parent[k][parent[k][u]]。接著,對於每個詢問O( lgn ),先讓兩個人的深度相同,再慢慢往上移但不要讓兩人的點相同(這個寫(想)法很酷,是iwi想到的,詳情可以看他的『邏輯腦』)。u, v 是所要詢問的兩點(假設兩點以再同一高度,若不同可以用十進位轉二進位的方法如法炮製),最後回傳的為他們的LCA。
for( int k = MAX ; k >= 0 ; k-- ) if( parent[k][v] != parent[k][u] ) u = parent[k][v], v = parent[k][u];
return parent[0][u]; //最後還要再往上爬一格才行(超酷><)
第二種:
這才是今天的重點,把它壓扁成一條線,做RMQ!想把樹壓成一條線,唯一作法:時間戳記。但今天要的可能出現在從 u 走到 v 之間的任意點,所以在一個點被邊『走到』都要記錄他的時間戳記,因為在他們的時間戳記之間的所有點的 lev 一定<= 他們的LCA。(若有人 > 他們的LCA,則代表 u 必須走超出他們LCA再走下來才會碰到 v,這樣LCA就不是他們的LCA了,矛盾)所以對於每一個詢問,用RMQ求出之間的最小值即為所求。
==============================================進入RMQ
首先,最基本的RMQ大家都熟到炸開了吧?!也就是所謂的線段樹解法,有點太老梗了在此便不多提。我想要說一下Sparse Table(稀疏的桌子)解法,簡稱ST算法。
//////////////////////////////////////////////////////////////////////////
ST算法:O(nlgn) - O(1),先建立一個表,tbl[x][k],代表a[i] { i = x ~ x+2^k-1 } 的最小值,而這個算法的精隨為:tbl[x][k] = tbl[x][k-1]+tbl[x+2^(k-1)][k-1] ,簡單精巧又快速的好方法。
/////////////////////////////////////////////////////////////////////////
+-1 RMQ 算法:O(n) - O(1),概念:塊狀分解(設c個一塊,共n個)
預處理:對n/c塊做ST -> O( (n/c) * lg(n/c) );
對所有零碎的可能狀況建表 -> O( 2^c*c^2 ); (你知道只會有2^c種,因為相鄰的接只差一)
詢問:用 ST+已有的零碎 -> O(1)
經過一番計算,可以發現 c = lgn/2時,預處理時間可以壓到O(n)
//////////////////////////////////////////////////////////////////////////
笛卡爾樹:(一個可以把序列轉換成樹的方式)
Definition: 根為此序列的min值,左子樹由min點左邊的序列所構成,右子樹則是右邊的。
Construction:
void 把一個節點放入一顆笛卡爾樹( int a[i], int root_id ){
if( 其比此樹的根值大) 把一個節點放入一棵笛卡爾樹( a[i], root_id*2+1 );
else 把此樹拔掉,已此點取代後,在把被拔掉的樹當成此點的左子樹;
}
 Property: 當要找出某區段L~R的RMQ,即為在此樹上二節點LCA的值。
Property: 當要找出某區段L~R的RMQ,即為在此樹上二節點LCA的值。
(原因:LCA的性質便是 l 節點在他的左子樹,而 r 節點在他的右子樹(一般特性),且其為一個包含 l 和 r 的區段中的min(笛卡爾樹),故其為l~r區段中的min值。)
//////////////////////////////////////////////////////////////////////////
今天要講的有LCA和RMQ(兩個關係匪淺的好玩有趣酷炫東西)
講完這個希望可以進入新的一個境界,並進入可怕的『字串』
=============================================入正文
LCA有兩種簡單的作法:
第一種:
我最常用的方法,就是用二分搜的方式。先以 O(nlgn) 做出parent[k][u],代表 u 往上2^k所到達的點,作法的精隨:parent[k+1][u] = parent[k][parent[k][u]]。接著,對於每個詢問O( lgn ),先讓兩個人的深度相同,再慢慢往上移但不要讓兩人的點相同(這個寫(想)法很酷,是iwi想到的,詳情可以看他的『邏輯腦』)。u, v 是所要詢問的兩點(假設兩點以再同一高度,若不同可以用十進位轉二進位的方法如法炮製),最後回傳的為他們的LCA。
for( int k = MAX ; k >= 0 ; k-- ) if( parent[k][v] != parent[k][u] ) u = parent[k][v], v = parent[k][u];
return parent[0][u]; //最後還要再往上爬一格才行(超酷><)
第二種:
這才是今天的重點,把它壓扁成一條線,做RMQ!想把樹壓成一條線,唯一作法:時間戳記。但今天要的可能出現在從 u 走到 v 之間的任意點,所以在一個點被邊『走到』都要記錄他的時間戳記,因為在他們的時間戳記之間的所有點的 lev 一定<= 他們的LCA。(若有人 > 他們的LCA,則代表 u 必須走超出他們LCA再走下來才會碰到 v,這樣LCA就不是他們的LCA了,矛盾)所以對於每一個詢問,用RMQ求出之間的最小值即為所求。
==============================================進入RMQ
首先,最基本的RMQ大家都熟到炸開了吧?!也就是所謂的線段樹解法,有點太老梗了在此便不多提。我想要說一下Sparse Table(稀疏的桌子)解法,簡稱ST算法。
//////////////////////////////////////////////////////////////////////////
ST算法:O(nlgn) - O(1),先建立一個表,tbl[x][k],代表a[i] { i = x ~ x+2^k-1 } 的最小值,而這個算法的精隨為:tbl[x][k] = tbl[x][k-1]+tbl[x+2^(k-1)][k-1] ,簡單精巧又快速的好方法。
/////////////////////////////////////////////////////////////////////////
+-1 RMQ 算法:O(n) - O(1),概念:塊狀分解(設c個一塊,共n個)
預處理:對n/c塊做ST -> O( (n/c) * lg(n/c) );
對所有零碎的可能狀況建表 -> O( 2^c*c^2 ); (你知道只會有2^c種,因為相鄰的接只差一)
詢問:用 ST+已有的零碎 -> O(1)
經過一番計算,可以發現 c = lgn/2時,預處理時間可以壓到O(n)
//////////////////////////////////////////////////////////////////////////
笛卡爾樹:(一個可以把序列轉換成樹的方式)
Definition: 根為此序列的min值,左子樹由min點左邊的序列所構成,右子樹則是右邊的。
Construction:
void 把一個節點放入一顆笛卡爾樹( int a[i], int root_id ){
if( 其比此樹的根值大) 把一個節點放入一棵笛卡爾樹( a[i], root_id*2+1 );
else 把此樹拔掉,已此點取代後,在把被拔掉的樹當成此點的左子樹;
}

(原因:LCA的性質便是 l 節點在他的左子樹,而 r 節點在他的右子樹(一般特性),且其為一個包含 l 和 r 的區段中的min(笛卡爾樹),故其為l~r區段中的min值。)
//////////////////////////////////////////////////////////////////////////
有了上述的基礎後-
當你碰上了RMQ,你可以先轉為笛卡爾樹求LCA,再轉回+-1RMQ,以 O(n) - O(1) 解決。
2012年7月15日 星期日
講講KMP好了
所謂的KMP,想要解決的問題如下:
給你兩個字串: A 和 B,問B是否為A的子字串?
(長度為 n 和 m)
於是你想到了一個爛作法(他有一個帥氣的名字叫naive啥鬼的):
枚舉所有在A上的起點,一一比對,看有沒有跟B一樣
時間複雜度:O( (n-m+1)*m )
這裡呢,我要奉上一個超讚的演算法,由罩神Knuth和他的夥伴所創出的KMP算法。
時間複雜度:O( n+m )
==============================廢話到這裡結束
先想想在爛作法中的一些智障缺點,你像下圖這樣比對了一段,但在後面發現你們並沒有辦法在這樣繼續下去了,你把下面的B向後移了一格,又要像剛剛那樣再試一次。

但事實上你已經比對過後面的那些了,這時候,如果可以 O(1) 知道要擺在下面四個位置的哪一個(如果可以還是要選第一個),這樣就不用再一次的重新比較剛剛比過的『灰色箭頭部分』。如此便可以很順利的跑過 n 個字母,並順利的以O(n)結束掉。


給你兩個字串: A 和 B,問B是否為A的子字串?
(長度為 n 和 m)
於是你想到了一個爛作法(他有一個帥氣的名字叫naive啥鬼的):
枚舉所有在A上的起點,一一比對,看有沒有跟B一樣
時間複雜度:O( (n-m+1)*m )
這裡呢,我要奉上一個超讚的演算法,由罩神Knuth和他的夥伴所創出的KMP算法。
時間複雜度:O( n+m )
==============================廢話到這裡結束
先想想在爛作法中的一些智障缺點,你像下圖這樣比對了一段,但在後面發現你們並沒有辦法在這樣繼續下去了,你把下面的B向後移了一格,又要像剛剛那樣再試一次。

但事實上你已經比對過後面的那些了,這時候,如果可以 O(1) 知道要擺在下面四個位置的哪一個(如果可以還是要選第一個),這樣就不用再一次的重新比較剛剛比過的『灰色箭頭部分』。如此便可以很順利的跑過 n 個字母,並順利的以O(n)結束掉。

其實剛剛你想要瞬間知道的就是,對於B字串,以『直線+兩顆點點』做結尾的所有後綴,哪一個可以和B的前綴完全相合(且合的越多越好)。
所以我們假設以 i 作結尾的後綴,最長可以和以 G[i] 做結尾的前綴相合。
當我們知道G[1]~G[i],可否推出G[i+1]呢?來討論一下:
假如B[i+1] == B[G[i]+1],那你就知道,G[i+1] = G[i]+1。
否則:去試B[G[G[i]]+1],再不行就是B[G[G[G[i]]]+1],試到ok 或 試到沒得試了(也就是0)

聽完之後,你想想可能會問為什麼不是O(m^2),但你知道G只會增加一,最多加到m,所以扣也只能扣m,整體來看就是O(m)。(前面的也是相同的情況)
code: http://codepad.org/JhbPTUVc
tioj 1698 Problem H 神殿裡的觸手
這幾題中最簡單的吧!
沒有任何的陷阱跟怪東西
就是一個Kruskal+找bridge
code: http://codepad.org/O6a4XRME
2012年7月14日 星期六
tioj 1697 Problem G 古墨西哥密碼
奸詐的題目,時間卡好緊==
題目特別解析:(普通解析可以看這裡XDD)
1. 找出 2L~2R 的質數表
2. 以1.的bool表建出一個有向圖(如果x then y成立,則由x連到y)
//簡單的部份到這裡為止
3. 這時你想要解的是:
找出A~B,使得可以在剛剛的有向圖中以<=K條路徑覆蓋A~B所有點
4. 但你只會算『在一個有向圖中最少要幾條簡單路徑覆蓋所有點』
(這裡要使用的技巧是二分圖匹配,而要解決這個問題,只需要把每一個點拆成入點和出點即可且入點和出點無任何關係,以此做最大匹配(x),所求的答案便是n-x,原因的話是因為沒有被匹配到的點,象徵著簡單路徑的終點(二分圖左半邊)和起點(二分圖右半邊))
5. 所以你便想用枚舉的方式,但發現時間複雜度O(V*V*V*E),TLE。這時,你發現可以用雙指針,而且可以將他放入二分圖匹配的步驟之中,瞬間將時間複雜度將為O(V*E)。
6. 最重要的一件事!在Bipartite的時候要從G[p].size()-1~0,不能反過來喔,原因應該跟機率有關,不討論了,但極重要,不這樣寫100%TLE。
code: http://codepad.org/a7gksiSK
題目特別解析:(普通解析可以看這裡XDD)
1. 找出 2L~2R 的質數表
2. 以1.的bool表建出一個有向圖(如果x then y成立,則由x連到y)
//簡單的部份到這裡為止
3. 這時你想要解的是:
找出A~B,使得可以在剛剛的有向圖中以<=K條路徑覆蓋A~B所有點
4. 但你只會算『在一個有向圖中最少要幾條簡單路徑覆蓋所有點』
(這裡要使用的技巧是二分圖匹配,而要解決這個問題,只需要把每一個點拆成入點和出點即可且入點和出點無任何關係,以此做最大匹配(x),所求的答案便是n-x,原因的話是因為沒有被匹配到的點,象徵著簡單路徑的終點(二分圖左半邊)和起點(二分圖右半邊))
5. 所以你便想用枚舉的方式,但發現時間複雜度O(V*V*V*E),TLE。這時,你發現可以用雙指針,而且可以將他放入二分圖匹配的步驟之中,瞬間將時間複雜度將為O(V*E)。
6. 最重要的一件事!在Bipartite的時候要從G[p].size()-1~0,不能反過來喔,原因應該跟機率有關,不討論了,但極重要,不這樣寫100%TLE。
code: http://codepad.org/a7gksiSK
2012年7月13日 星期五
Cocos2D
@property float value;
其實就是
- (float)value;
- (void)setValue:(float)newValue;
的宣告(?!)
要在.m檔加上@synthesize value
-----------------------------------------------------------------------------------------------
製作MENU:
CCMenuItemImage *OBJECT = [CCMenuItemImage itemWithNormalImage:@"OBJECT.png" //顯示的
selectedImage:@"OBJECT.png" //操作的
target: self //放在哪裡?!
selector:@selector(FUNC:)]; //點了後要做什麼事
CCMenu *MENU = [CCMenu menuWithItems:OBJECT, nil];
-(void) FUNC:(id)sender{ }
切換Scene:
[[CCDirector sharedDirector]replaceScene:[CCTransitionFlipX transitionWithDuration:1 scene:[SCENE node]]];
移動Sprites:
id Act = XXXXXXX;
id Rac = [Act reverse]; //和Act 恰恰相反
id Seq = [CCSequence actions: Act, Rac, nil ]; //一連串的動作(若一步步執行,會全部黏在一起)
id Spa = [CCSpawn actions: Act, Rac, nil ]; //正統的黏在一起的動作
id Rep = [CCRepeat actionWithAction: Act, times 3];//重複動作
id ReF = [CCRepeatForever actionWithAction: Act];//無限重複
id Eas = [CCEaseInOut actionWithAction: Act, rate 3];//有加速度
[CCJumpBy actionWithDuration:0.2 position:ccp(0,0) height: 200 jumps: 2]//跳躍多少
[CCMoveBy actionWithDuration:0.2 position:ccp(40,20)]//移多少
[CCScaleBy actionWithDuration:0.2 scale:3];//放大多少
ps. 改成To,就會是『變成原來的幾倍』,非『變成現在的幾倍』
//停住他的動作
[miku stopAllActions];
//執行某一動作
[miku runAction:*CCACTION];
-----------------------------------------------------------------------------------------------
製作MAP:
在 .h 檔中
@interface HelloWorldLayer : CCLayer
{
CCTMXTiledMap *theMap;
CCTMXLayer *bgLayer;
}
@property (nonatomic, retain) CCTMXTiledMap *theMap;
@property (nonatomic, retain) CCTMXLayer *bgLayer;
在 .m 檔中
-(id) init
{
if( (self=[super init]) ) {
self.theMap = [CCTMXTiledMap tiledMapWithTMXFile:@"bg.tmx"];
self.bgLayer = [theMap layerNamed:@"BG"];
[self addChild:theMap z:-1]; // z=-1是位在第幾層
}
return self;
}
- (void) dealloc
{
//將他們的記憶體釋放
self.theMap = nil;
self.bgLayer = nil;
[super dealloc];
}
-----------------------------------------------------------------------------------------------
基本非可操控部分:
iphone: 480 * 320
圖:resources
CCSprite *OBJECT;
在 init 裡頭的 if 裡頭
// 印出OBJECT
OBJECT = [CCSprite spriteWithFile: @"OBJECT.png" ];
OBJECT.position = ccp( X座標, Y座標 );
[self addChild: OBJECT];
// 移動OBJECT(依據測試dt為一固定值)
[self schedule:@selector(FUNC:):];
-(void) FUNC:(ccTime) dt{
miku.position = ccp( miku.position.x+A*dt, miku.position.y+B*dt ); // A, B 是常數
}
ps: 依據我的推設,函式打+是在每次都會做,打-則是要被呼叫。
-----------------------------------------------------------------------------------------------
觸控式部分:
#import "CCTouchDispatcher"
//舊的(不贊成使用)
[[CCTouchDispatcher sharedDispatcher] addTargetedDelegate:self priority:0 swallowsTouches:YES];
//新版(較佳?!)
[[[CCDirector sharedDirector] touchDispatcher] addTargetedDelegate:self priority:0 swallowsTouches:YES];
四種Touch方式:
ccTouchBegan, ccTouchEnded, ccTouchMove, ccTouchCancelled
因為一定要有開始所以一定要加:
-(BOOL)ccTouchBegan:(UITouch *)touch withEvent:(UIEvent *)event{
return YES;
}
當把手移開時要做什麼勒?://得到位置
-(void)ccTouchEnded:(UITouch *)touch withEvent:(UIEvent *)event{
//一開始得到的POS是UIKit的位置,以左上當(0, 0),但openGL是以左下當(0,0)
CGPoint POS = [touch locationInView:[touch view]];
CGPoint CON = [[CCDirector sharedDirector]convertToGL:POS];
}
2012年7月11日 星期三
tioj 1694 Problem D 你的重生之旅
我真的很喜歡ABCLS的題目XD
雖然code很長,而且我寫了超久(+ debug)
我開了四個重要的陣列,a, b, c, d
a[i]: 第 1 ~ i 塊自己的逆序數對和(nlgn)
b[i][j]: 第 i 個對第 1~j 塊的逆序數對和(n*sqrt(n) -> 要想一下)
c[i][j]: sigma( k = 1 ~ i )第 k 塊對第 k+1~j 塊的逆序數對和(n*sqrt(n))
d[0][i]: 第 i 個對自己所屬的塊中的右邊的逆序數對(n*sqrt(n))
d[1][i]: 第 i 個對自己所屬的塊中的左邊的逆序數對(n*sqrt(n))
For every query:
用 a 和 b 做出完全包住 『所問的範圍』 的方塊的逆序數對數量O(1)
用 c 和 d 扣掉多出來不在『所問的範圍』的那些逆序數對 O(sqrt(n))
再用神祕的方法O(L) sort 兩坨多出來的,並將他們的逆序數對數加回來O(sqrt(n))
最重要的是,每一塊的數量!
由於我寫的code使得時間複雜度為
T( 5Qx + 4n^2/x + nlgx + n + 0.5*(n^2) / (x^2) )(x為每一塊的數量)
有些不重要可以劃掉 -> T( 5Qx + 4n^2/x )要最小,用算幾不等式
可以得到想要最小時, x = sqrt( 4/5 ) * n / sqrt( q )
code: http://codepad.org/Q1v7RMu8
2012年7月9日 星期一
tioj 1624 快樂設置道路
重新見識到我的debug功力之爛++
爛到透光了,一切敗在sort的位置中
其實就三維DP啦,不是很重要的題目
寫這篇是要說,當把東西移掉時,要記得全部都改
(頭腦要清楚才行)
code: http://codepad.org/NACX8veI
爛到透光了,一切敗在sort的位置中
其實就三維DP啦,不是很重要的題目
寫這篇是要說,當把東西移掉時,要記得全部都改
(頭腦要清楚才行)
code: http://codepad.org/NACX8veI
2012年7月8日 星期日
PA 2010 R3-Squared Words
不是這麼想說,但這提真的很水
另外一提我怎麼寫都寫不出來,哪天再回來寫。
而這提其實就枚舉割點,然後LCS
不要以為會TLE,用程式sigma一下就會發現其實是會AC
code: http://codepad.org/uBOk4Tf5
另外一提我怎麼寫都寫不出來,哪天再回來寫。
而這提其實就枚舉割點,然後LCS
不要以為會TLE,用程式sigma一下就會發現其實是會AC
code: http://codepad.org/uBOk4Tf5
2012年7月5日 星期四
PA2010 R0~R2專區
Rectangles: 枚舉 http://codepad.org/aPJ29Ffi
Orienteering: unique把相同的移掉 http://codepad.org/k4w8eOyD
Mushroom: 來回走在兩相鄰點之間 http://codepad.org/wkxCGXbi
Coins: 用map存o-m*r的最左邊,每次都查看 http://codepad.org/HNfcidQc
Orienteering: unique把相同的移掉 http://codepad.org/k4w8eOyD
Mushroom: 來回走在兩相鄰點之間 http://codepad.org/wkxCGXbi
Coins: 用map存o-m*r的最左邊,每次都查看 http://codepad.org/HNfcidQc
2012年7月3日 星期二
tioj 1637 我愛台灣
維持stack嚴格遞減?!
看想法啦,而且東西都丟在stack裡好像記憶體變很小
預估有6000K,但出來只有28K
code: http://codepad.org/Ey9tiX3a
看想法啦,而且東西都丟在stack裡好像記憶體變很小
預估有6000K,但出來只有28K
code: http://codepad.org/Ey9tiX3a
2012年7月2日 星期一
tioj 1443 遞迴問題
說真的,好久沒寫程式了,一直努力怕被當的說> <
終於暑假了,今天寫了不錯的怪題?!
這題其實就是給 n ,問 lg(n+1) 的整數部分
(這部份我是印出一大堆東西後判斷出來的)
本來一直怕會有誤差(n大約是100000位吧)
所以寫別的作法,如大數之類的,但100%超時==
最後決定亂寫,直接用換底XD ((居然沒有以二為底的log OoO
code: http://codepad.org/cFB4BO4y
終於暑假了,今天寫了不錯的怪題?!
這題其實就是給 n ,問 lg(n+1) 的整數部分
(這部份我是印出一大堆東西後判斷出來的)
本來一直怕會有誤差(n大約是100000位吧)
所以寫別的作法,如大數之類的,但100%超時==
最後決定亂寫,直接用換底XD ((居然沒有以二為底的log OoO
code: http://codepad.org/cFB4BO4y
訂閱:
意見 (Atom)